지난 글에 이어 elasticsearch를 적용하는 글을 작성해보겠다.
1. Elasticsearch 설치
$ docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.0
$ docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.0- docker를 통해 elasticsearch를 설치한다. 나의 경우 최신 버전에 대한 사용법이 익숙치 않아 7.10.0 버전을 설치했다.
- 실행은 싱글 노드로 실행되도록 설정했다. 내부에서는 노드간 9300포트로 통신한다는 의미로 -p 9300:9300을 설정했다.
2. 의존성 설정

위의 그림과 같이 현재 ES의 버전에 맞는 의존성을 추가해준다.
3. document 설정

이후 위 그림과 같이 JPA의 @Entity와 같이 @Document 어노테이션으로 해당 클래스가 ES의 인덱스임을 알린다.
4. Repository 설정

Spring data JPA와 같이 ElasticsearchRepository를 상속받는 리포지토리를 생성한다. 이때 현재 스프링 부트의 버전과 Spring data Elasticsearch의 버전이 맞지 않아 CRUD작업에 문제가 생겨 CrudRepository도 함께 상속 받았다.
5. Elasticsearch Cofiguration 생성

위의 내용은 코드만 봐도 직관적으로 알 수 있을 것이다. 저장할 노드의 주소를 설정하고 생성해줬다.
6. 이후 Spring data JPA를 사용할 때와 똑같이 서비스, 컨트롤러를 생성해주면 성공적으로 데이터가 저장이 되고 조회가 된다.
elasticsearch노드 주소/인덱스명/_search에 get요청을 보내면 해당 인덱스에 저장된 데이터를 확인할 수 있다.
아래와 같이 json 형식으로 저장되는 것을 확인할 수 있다.
나의 경우 아래와 같이 item을 생성했다.

url로 조회시 조회된 데이터

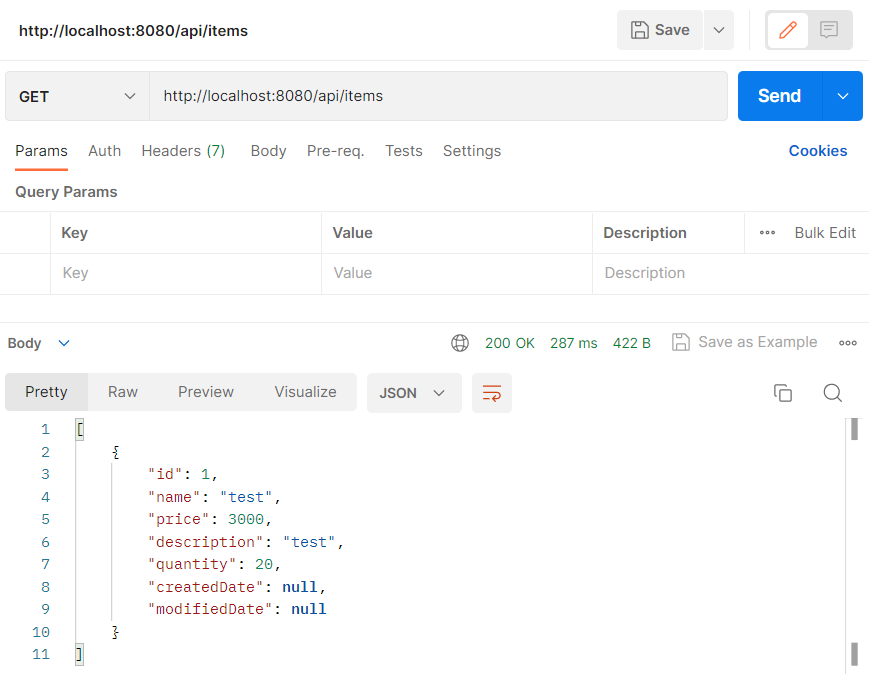
postman으로 조회시 조회된 데이터
마치며
엘라스틱 서치를 적용해봤다. 아직 1개의 데이터를 조회하기 때문에 성능상 이점을 느끼지는 못했다. 다음의 글에서 1만개의 데이터를 넣고 성능을 비교하고 키바나를 적용하며 데이터를 시각화 해보겠다.
'프로젝트 > 고민' 카테고리의 다른 글
| Elasticsearch 적용 이야기: Kibana 적용기 (1) | 2023.05.13 |
|---|---|
| Elasticsearch 도입 이야기: 성능 테스트 하기 (0) | 2023.05.08 |
| Elasticsearch 도입 이야기: Elasticsearch란? (0) | 2023.05.07 |
| 소셜로그인에 팩토리 메소드 패턴 적용하기 (0) | 2023.04.01 |
| 전략패턴을 이용한 리팩토링 (0) | 2023.03.26 |



