프로그래머스의 level2에 있는 방문길이라는 문제를 풀었다. 여기서 Equals와 HashCode를 재정의 하여 문제를 풀었기 때문에 이번 기회에 Equals와 HashCode를 같이 재정의 해야하는 이유를 설명해 보겠다.
문제의 내용은 다음과 같다.
https://school.programmers.co.kr/learn/courses/30/lessons/49994
게임 캐릭터를 4가지 명령어를 통해 움직이려 합니다. 명령어는 다음과 같습니다.
- U: 위쪽으로 한 칸 가기
- D: 아래쪽으로 한 칸 가기
- R: 오른쪽으로 한 칸 가기
- L: 왼쪽으로 한 칸 가기
캐릭터는 좌표평면의 (0, 0) 위치에서 시작합니다. 좌표평면의 경계는 왼쪽 위(-5, 5), 왼쪽 아래(-5, -5), 오른쪽 위(5, 5), 오른쪽 아래(5, -5)로 이루어져 있습니다.

예를 들어, "ULURRDLLU"로 명령했다면

- 1번 명령어부터 7번 명령어까지 다음과 같이 움직입니다.
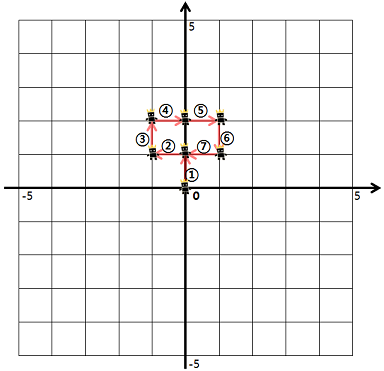
- 8번 명령어부터 9번 명령어까지 다음과 같이 움직입니다.

이때, 우리는 게임 캐릭터가 지나간 길 중 캐릭터가 처음 걸어본 길의 길이를 구하려고 합니다. 예를 들어 위의 예시에서 게임 캐릭터가 움직인 길이는 9이지만, 캐릭터가 처음 걸어본 길의 길이는 7이 됩니다. (8, 9번 명령어에서 움직인 길은 2, 3번 명령어에서 이미 거쳐 간 길입니다)
단, 좌표평면의 경계를 넘어가는 명령어는 무시합니다.
예를 들어, "LULLLLLLU"로 명령했다면

- 1번 명령어부터 6번 명령어대로 움직인 후, 7, 8번 명령어는 무시합니다. 다시 9번 명령어대로 움직입니다.

이때 캐릭터가 처음 걸어본 길의 길이는 7이 됩니다.
명령어가 매개변수 dirs로 주어질 때, 게임 캐릭터가 처음 걸어본 길의 길이를 구하여 return 하는 solution 함수를 완성해 주세요.
제한사항
- dirs는 string형으로 주어지며, 'U', 'D', 'R', 'L' 이외에 문자는 주어지지 않습니다.
- dirs의 길이는 500 이하의 자연수입니다.
입출력 예
dirsanswer
| "ULURRDLLU" | 7 |
| "LULLLLLLU" | 7 |
입출력 예 설명
입출력 예 #1
문제의 예시와 같습니다.
입출력 예 #2
문제의 예시와 같습니다.
문제를 보자마자 내가 생각한 알고리즘은 이동 전 좌표와 이동 후 좌표를 변수로 갖고있는 클래스를 만들어 이 좌표들을 고유한 값으로 같도록 equals와 hashCode 메소드를 재정의해서 HashSet에다가 저장하는 방식이 가장 먼저 떠올랐다. 이를 코드를 구현한 결과가 다음과 같다. 여기서 하나 주의해야 할점은 캐릭터가 지나가는 길이기 때문에 (1,2) (2,3)을 잇는 직선은 (2,3) (1,2)와 같다는 점이다. 따라서 좌표를 받을때 더 큰 값이 end좌표가 되도록 설정했다.
import java.util.*;
class Position {
int startX, startY, endX, endY;
public Position(int startX, int startY, int endX, int endY) {
if (startX > endX) {
int temp = startX;
this.startX = endX;
this.endX = temp;
} else {
this.startX = startX;
this.endX = endX;
}
if (startY > endY) {
int temp = startY;
this.startY = endY;
this.endY = temp;
} else {
this.startY = startY;
this.endY = endY;
}
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (!(o instanceof Position))
return false;
return (this.startY == ((Position) o).startY && this.startX == ((Position) o).startX)
&& (this.endY == ((Position) o).endY && this.endX == ((Position) o).endX);
}
@Override
public int hashCode() {
return Objects.hash(startX, startY, endX, endY);
}
}
class Solution {
public int solution(String dirs) {
int answer = 0;
HashSet<Position> set = new HashSet<>();
int x = 0;
int y = 0;
for(int i = 0; i < dirs.length(); i++) {
int startX = x;
int startY = y;
if(dirs.charAt(i) == 'U') {
y++;
} else if (dirs.charAt(i) == 'D') {
y--;
} else if (dirs.charAt(i) == 'L') {
x--;
} else {
x++;
}
if (x > 5) {
x--;
continue;
}
if (y > 5) {
y--;
continue;
}
if (x < -5) {
x++;
continue;
}
if (y < -5) {
y++;
continue;
}
Position position = new Position(startX, startY, x, y);
set.add(position);
}
answer = set.size();
return answer;
}
}결과는 정답처리가 되었다. 우리는 흔히 hashMap이나 hashSet, HashTable등에 관한 자료구조는 객체가 갖고있는 고유의 Hash코드를 키로 갖고 있는것으로 알고 있다. 그렇다면 우리는 Hash코드를 생성하는 메소드만 재정의 해주면 되지 않을까? 라는 생각을 하게 된다. 하지만 HashCode만 재정의 해줄 경우 결과는 다음과 같이 발생한다.

결과는 같은 hash값을 갖더라도 다른 객체로 판단되어 HashSet안에 데이터가 들어가게 된다. 왜 이렇게 되는지 hashSet에 있는 add 메소드에 대해서 살펴봤다.


위의 코드와 같이 HashSet 클래스 내부에는 HashMap이 존재하며, add 메소드는 제너릭으로 선언된 E 타입을 매개변수로 받아 클래스 내부에 있는 해시맵의 put메소드를 호출해 안에 값이 존재하는지에 대해 boolean형으로 반환한다.
이것만으로는 equals를 왜 같이 정의해야하는지 알 수 없으므로 map에서 호출하는 put메소드를 따라가 보자.

여기서는 putVal이라는 메소드에 해당 key의 해시값과, key자체, 키에 해당하는 value를 넣는것을 확인할 수 있다.
다음은 putVal 메소드이다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}putVal메소드는 상당히 복잡하게 구현되어 있는데, if문을 살펴보면 hash값과 key에 해당하는 equals메소드를 이용해 이미 존재하는 값인지 아닌지에 대해서 유효성을 검사한다. 이를 통해 우리는 hash코드를 이용하는 Collection은 HashCode 뿐만 아니라 equals까지 사용하여 유효성을 두번 검사하는것을 알았고, hashCode메소드와 equals 메소드를 같이 정의해주어야 하는 이유도 알 수 있다.
결론적으로 우리는 hash를 이용한 컬렉션을 사용하지 않을때 equals 메소드를 재정의 하고 싶은 경우 equals 메소드만 재정의 하여 객체가 같은 객체인지 다른 객체인지 논리적으로는 판단할 수 있을 것이다. 하지만 이 경우 두 객체의 hashCode는 다른 값을 갖게 되는데 이 두 객체가 과연 같다고 할 수 있을까? 또한 이 객체를 hash를 이용한 자료구조에 넣을때 서로 다른 객체로 판단이 되어 문제가 발생하기도 한다. 따라서 우리는 equals 메소드 또는 hashCode메소드를 재정의 할때 두 메소드를 함께 정의해 논리적 동등성과 물리적 동등성 모두 갖추게 해야할 필요가 있다.
'프로젝트' 카테고리의 다른 글
| @Transactional과 AOP (0) | 2023.02.10 |
|---|---|
| mysql 쿼리 실행 계획 #2 (0) | 2023.01.28 |
| mysql 쿼리 실행 계획 #1 (2) | 2023.01.28 |


